Convert Email Body from HTML format to Text
Introduction:
We had a requirement , wherein when an Email is received a Case will be created in CRM and the body of the email will be set the description of the case. However we faced a problem because the Email body was in HTML format so we have to convert it and set it as the description.
Solution:
We have to write a plugin in which just take the HTML part of the email and eliminate every HTML tags so that we can get the Text part of the body.
Steps:
- Register the plugin in PostOperation PipeLine Stage and in Asynchronous Mode.
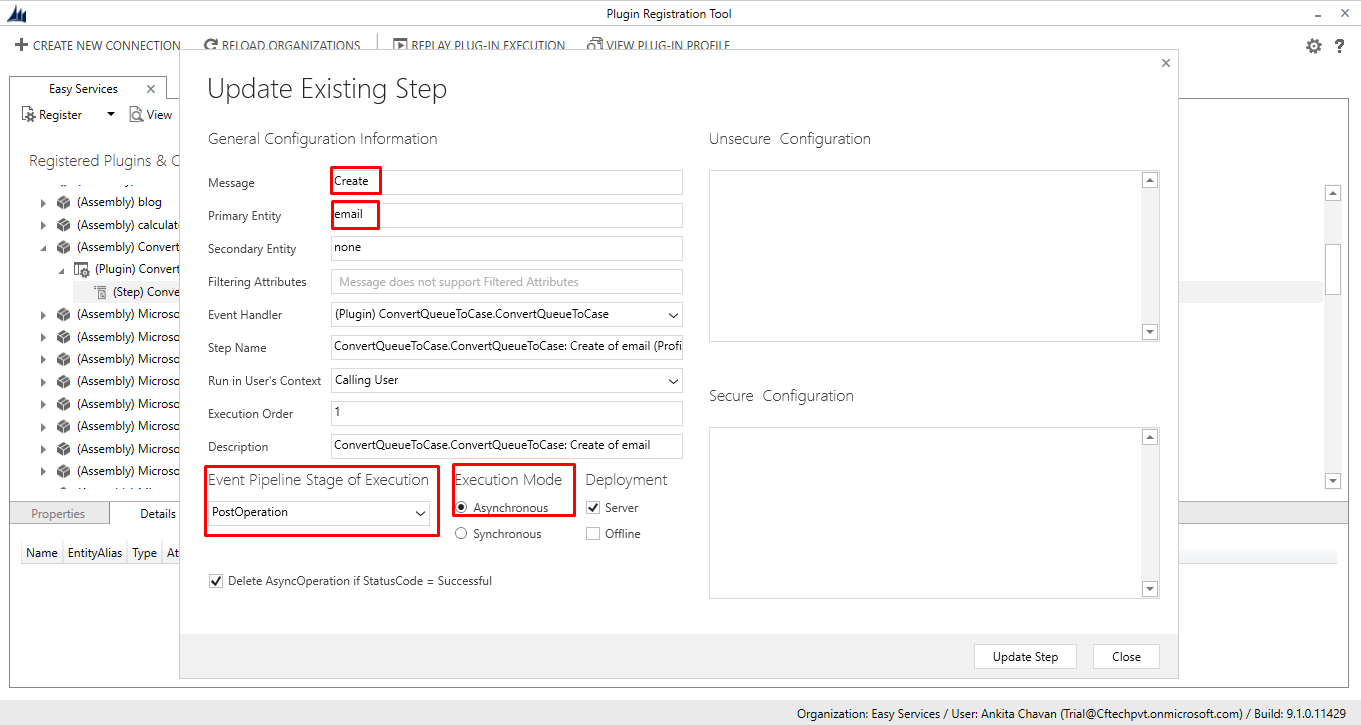
- First, get the body of Email in a String variable and call the function.
string description = currentRecord.GetAttributeValue<string>(Email.ATTR_DESCRIPTION); string actualDescription = StripHTML(description);
3.Then write a function to convert all the HTML Tags in the following way.
private static string StripHTML(string source)
{
try
{
string result;
// Remove HTML Development formatting
// Replace line breaks with space
// because browsers inserts space
result = source.Replace("\r", " ");
// Replace line breaks with space
// because browsers inserts space
result = result.Replace("\n", " ");
// Remove step-formatting
result = result.Replace("\t", string.Empty);
// Remove repeating spaces because browsers ignore them
result = System.Text.RegularExpressions.Regex.Replace(result,
@"( )+", " ");
// Remove the header (prepare first by clearing attributes)
result = System.Text.RegularExpressions.Regex.Replace(result, @"<( )*head([^>])*>", "<head>", System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result, @"(<( )*(/)( )*head( )*>)", "</head>",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,"(<head>).*(</head>)", string.Empty,System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// remove all scripts (prepare first by clearing attributes)
result = System.Text.RegularExpressions.Regex.Replace(result,@"<( )*script([^>])*>", "<script>",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"(<( )*(/)( )*script( )*>)", "</script>",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
//result = System.Text.RegularExpressions.Regex.Replace(result,
//@"(<script>)([^(<script>\.</script>)])*(</script>)",
//string.Empty,
// System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"(<script>).*(</script>)", string.Empty,System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// remove all styles (prepare first by clearing attributes)
result = System.Text.RegularExpressions.Regex.Replace(result, @"<( )*style([^>])*>", "<style>",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"(<( )*(/)( )*style( )*>)", "</style>",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,"(<style>).*(</style>)", string.Empty,System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// insert tabs in spaces of <td> tags
result = System.Text.RegularExpressions.Regex.Replace(result,@"<( )*td([^>])*>", "\t",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// insert line breaks in places of <BR> and <LI> tags
result = System.Text.RegularExpressions.Regex.Replace(result,@"<( )*br( )*>", "\r",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result, @"<( )*li( )*>", "\r",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// insert line paragraphs (double line breaks) in place
// if <P>, <DIV> and <TR> tags
result = System.Text.RegularExpressions.Regex.Replace(result,@"<( )*div([^>])*>", "\r\r",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"<( )*tr([^>])*>", "\r\r",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"<( )*p([^>])*>", "\r\r",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// Remove remaining tags like <a>, links, images,
// comments etc - anything that's enclosed inside < >
result = System.Text.RegularExpressions.Regex.Replace(result,@"<[^>]*>", string.Empty,System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// replace special characters:
result = System.Text.RegularExpressions.Regex.Replace(result, @" ", " ",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"•", " * ",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"‹", "<",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"›", ">",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"™", "(tm)",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result, @"⁄", "/",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"<", "<",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@">", ">",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"©", "(c)",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,@"®", "(r)",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// Remove all others.
result = System.Text.RegularExpressions.Regex.Replace(result,@"&(.{2,6});", string.Empty,System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// for testing
// System.Text.RegularExpressions.Regex.Replace(result,
//this.txtRegex.Text,string.Empty,
// System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// make line breaking consistent
result = result.Replace("\n", "\r");
// Remove extra line breaks and tabs:
// replace over 2 breaks with 2 and over 4 tabs with 4.
// Prepare first to remove any whitespaces in between
// the escaped characters and remove redundant tabs in between line breaks
result = System.Text.RegularExpressions.Regex.Replace(result,"(\r)( )+(\r)", "\r\r",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result, "(\t)( )+(\t)", "\t\t",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,"(\t)( )+(\r)", "\t\r",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result, "(\r)( )+(\t)", "\r\t",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// Remove redundant tabs
result = System.Text.RegularExpressions.Regex.Replace(result,"(\r)(\t)+(\r)", "\r\r",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// Remove multiple tabs following a line break with just one tab
result = System.Text.RegularExpressions.Regex.Replace(result,"(\r)(\t)+", "\r\t",System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// Initial replacement target string for line breaks string breaks = "\r\r\r";
// Initial replacement target string for tabs string tabs = "\t\t\t\t\t";
for (int index = 0; index < result.Length; index++)
{
result = result.Replace(breaks, "\r\r");
result = result.Replace(tabs, "\t\t\t\t");
breaks = breaks + "\r";
tabs = tabs + "\t";
}
// That's it.
return result;
}
catch
{
//MessageBox.Show("Error");
return source;
}
}
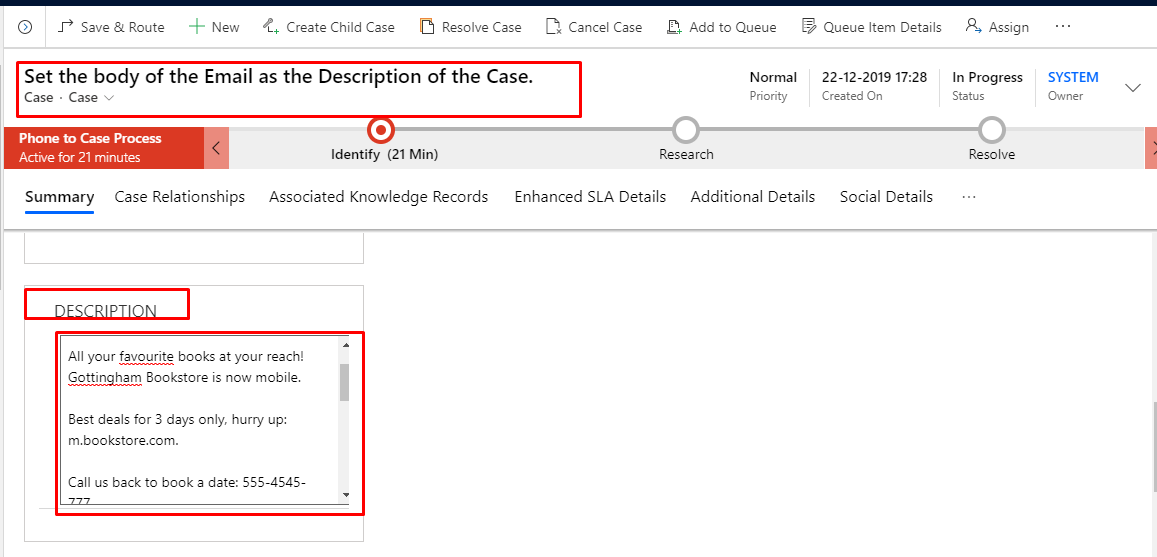
4. This is the Output.
- This is the Test Email that is been send to test.
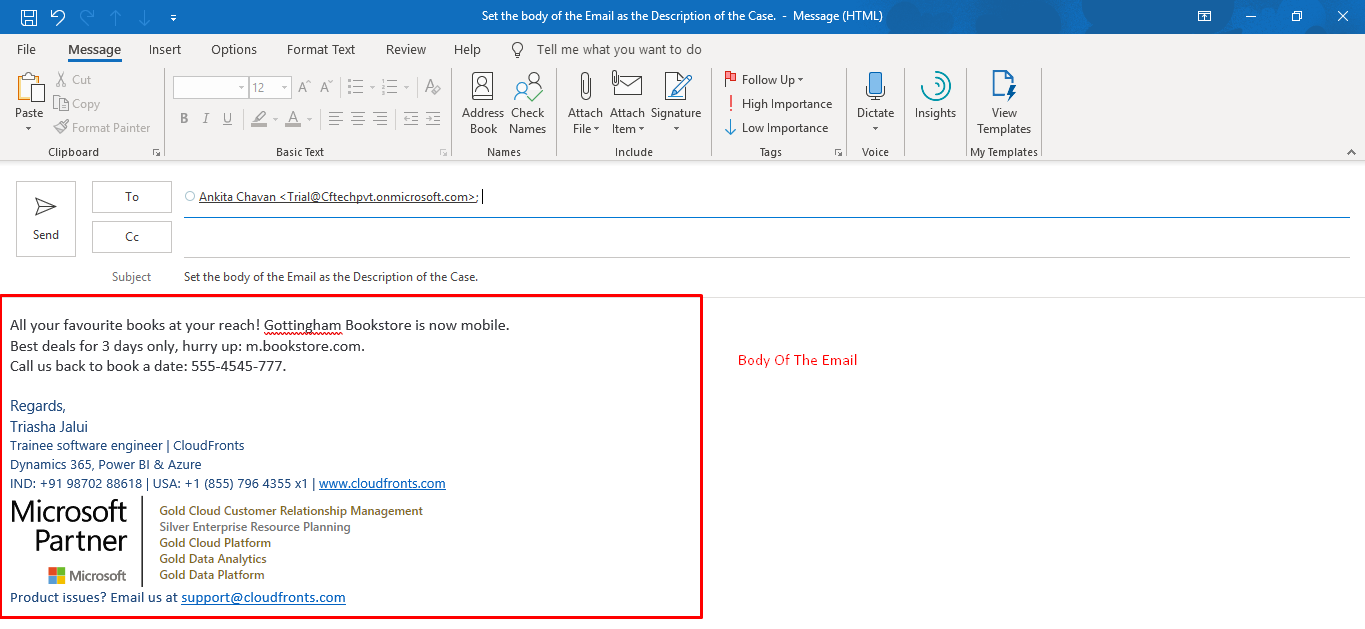
- This is the email that is received in the Dynamics 365 CRM.

- This is the Case which is created.

-
The description of the Case is the same as the Email